
https://arxiv.org/abs/2402.17764
Introduction
機械学習モデルの量子化とは、パラメタを連続の値ではなく、指定の離散の値しかとらないようにする。その結果、モデルを保持するためのデータをかなり削れる。もし精度の低下がそこまででなければね!
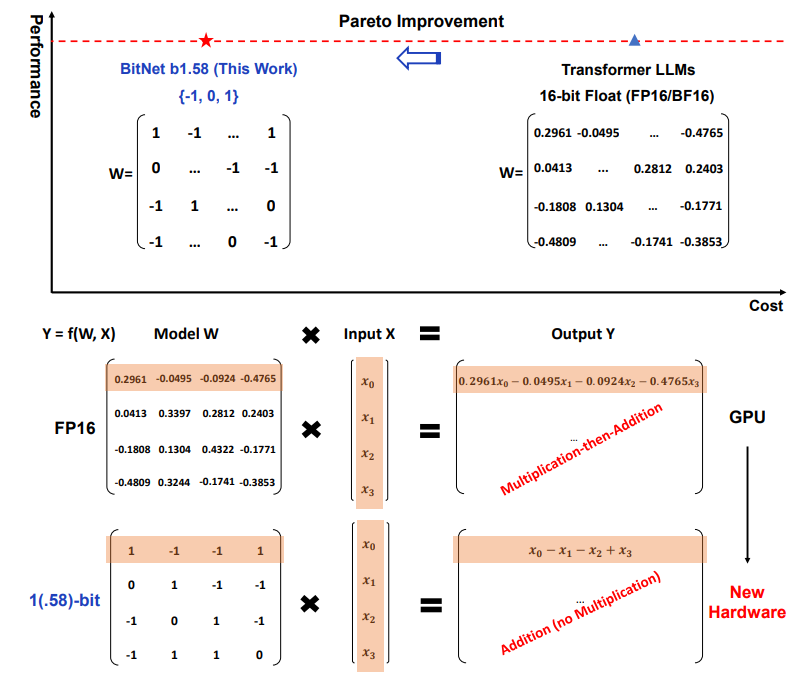
このように、-1, 0, +1だけで量子化できたら、加減算だけで計算でき、乗算ユニットが不要になる。それによって、
- 電力消費が減る。
- サイズが小さいので、DRAMだけでなく、SRAM(より早いけど1bit当たりの値段が高いメモリ)への転送できる量も増えて結果的に計算が早くなる。
16bitのfloatを、8, 4bitにどんどん縮めていく先行研究は結構ある。最終的に、1bitのみ取る=パラメタが0, 1だけのBitNetという言語モデルも開発されている。
この研究では、の3つの状態を持つ言語モデルを作り、性能がそこまで低下しないことを示した。
なので、1.58bitという。
-1, 0, +1の3つの状態を持たせることで、0という特徴フィルタリングを明示的にサポートすることで、1bitのLLMの性能を大幅に向上できる。
Bitnet b1.58
BitNetのアーキテクチャをそのまま使っている。ただし、線形層 nn.Linear() の代わりに、 BitLinear() へ置き換えただけ。
BitNetとは何か
BitNetのアーキテクチャは、以下のようなもの。
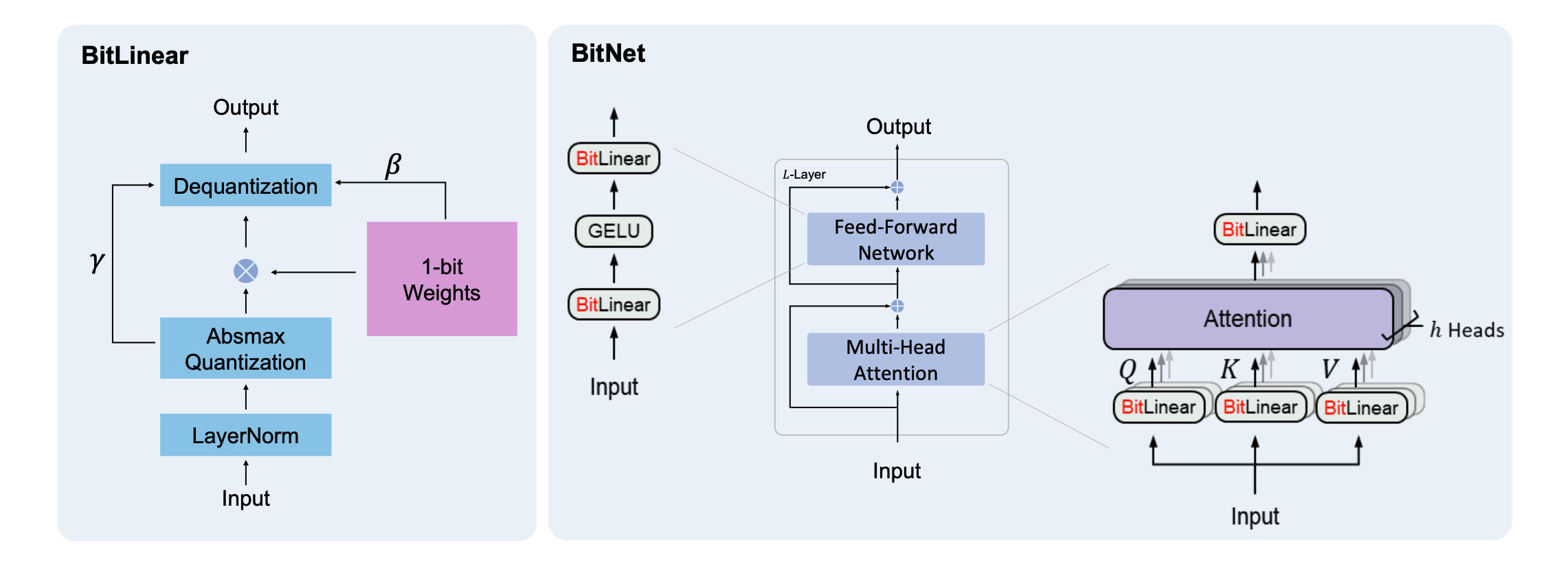
- 通常のTransformerと違うのは、線形層の代わりに、BitLinearを導入している。
- BitLinearとは、以下のようなもの。
- Layer Normalizationをする。これは通常の線形層と同じ。
- 学習時は重みは連続値であるが、推論時は量子化して、コンパクトにする。
- 以下のように絶対値量子化を行う。下述のように取りえる量子化後の値に近い方に丸める。
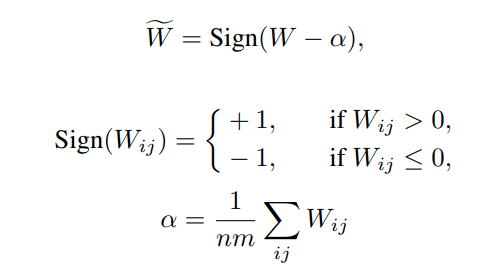
- 以下のように絶対値量子化を行う。下述のように取りえる量子化後の値に近い方に丸める。
- 推論時、入力データは同様に量子化する。量子化で使えるデータに対して以下のようの関数で、近くの値に丸める。
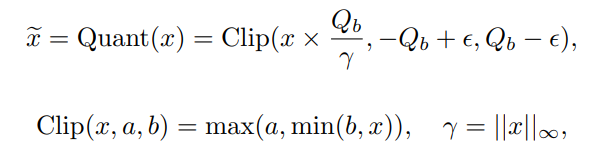
- ReLUのような活性化関数は、量子化するときに、正となる値だけ取るようにする。これは実質から、にそのままシフトさせる。どちらおの値で離散化させる。
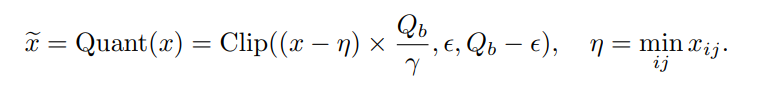
- お互い離散化した後に、で計算する、
- 終わった後に、離散化された計算データを連続値にまた戻す。これは、個のステージを、本来のmaxはなので、それを乗じるみたい。
- 全体的には以下のようにする。
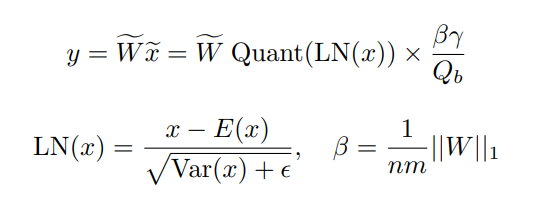
どのように量子化するか
重み行列を平均絶対値でプーリングして、各値をに近い値に丸める事だけ違う。